Résumé : l'étiquetage de texte est une tâche incontournable, décisive et difficile. Quelles représentations linguistiques choisir pour la réaliser ? Doit-on désambiguďser entičrement la morphologie ? Peut-on représenter l'ambiguďté localement, indépendamment du chaînage syntaxique ?
L'ambiguďté morphologique est une composante importante des médiocres performances des analyseurs syntaxiques. Ceux-ci ont ŕ parcourir en temps réel un nombre d'hypothčses considérable dű non seulement ŕ la complexité des rčgles de réécriture, mais aussi au nombre d'analyses morphologiques résultant de la lemmatisation. Les temps de traitement deviennent exponentiels et inadaptés ŕ la tâche, notamment pour des applications industrielles qui utilisent des dictionnaires de taille réelle, oů des lexicographes de métier ont répertorié toutes les ambiguďtés attestées en langue.
La réduction de l'ambiguďté morphologique avant l'entrée dans l'analyse syntaxique proprement dite est donc une nécessité incontournable qui a fait le succčs d'une nouvelle génération de grammaires, les grammaires de désambiguďsation.
Ces grammaires, bien qu'elles soient dédiées ŕ la désambiguďsation morphologique, n'en introduisent pas moins un changement d'axe dans le cours de l'analyse : avec elles, on passe du paradigmatique au syntagmatique. Cela n'est pas sans conséquences sur la représentations des données. C'est ce que nous essaierons de démontrer dans cet article1.
Quel type d'information exploitent les grammaires de désambiguďsation ?
A la différence des autres grammaires, les grammaires de désambiguďsation ne manipulent pas de syntagmes (sauf Vergne [VERGNE 94], mais syntagmes non-récursifs), puisque leur rôle est précisément de réduire l'ambiguďté morphologique pour faciliter la construction syntagmatique. Si la segmentation en "mots", phrases ou propositions a déjŕ été faite par la lemmatisation, le seul niveau de représentation accessible ŕ ce stade est le lemme, caractérisé par sa graphie, sa catégorie, sa sous-catégorie et ses valeurs flexionnelles (et dans le meilleur des cas fonctionnelles).
Ce qu'exploitent les grammaires de désambiguďsation, qu'elles soient statistiques [CHURCH 88] ou par rčgles, ces sont des contraintes sur les suites d'unités morphologiques, pour exclure en contexte les analyses hautement improbables ou impossibles. On travaille donc sur la forme de surface [KARLSSON 90], [VOUTILAINEN 94].
La longueur des suites examinées varie suivant les systčmes. Les systčmes statistiques qui manipulent des bigrammes ou des trigrammes sont limités ŕ des suites de longueur 2 ou 3. Les systčmes par rčgles opčrent dans les limites de la phrase ou de la proposition : ŕ l'intérieur de cette limite, l'empan de la fenętre d'exploration du contexte est aussi large que nécessaire2.
Dans les grammaires de contraintes, on peut interroger des contextes trčs étendus, ce qui permet de mettre en relation des éléments parfois trčs distants :
Les grammaires de désambiguďsation par contraintes sont des systčmes intelligents (par opposition aux systčmes statistiques) capables de tirer parti des propriétés linguistiques marquées en surface : relations d'ordre, contraintes distributionnelles et de rection. Sans tous les cas, on se sert du contexte pour désambiguďser. Les éléments qui appellent obligatoirement un régissant ou un dépendant sont exclus en l'absence de celui-ci. Le noyau verbal et la gauche du syntagme nominal sont ŕ cet égard les plus riches en contraintes. C'est probablement pourquoi l'exemple de contrainte le plus percutant restera encore pour longtemps l'interdiction de la suite DET-V.
Le quotidien du grammairien qui travaille dans ce cadre est donc fait de linguistique distributionnelle et dépendancielle. Il émet des contraintes trčs simples et linguistiquement fondées du type :
Puis, il formalise ces contraintes sous forme d'expressions réguličres dont la syntaxe varie d'un systčme ŕ l'autre. Voici un exemple de rčgle écrite avec SAM2 d'Erli3.
On voit donc clairement ici qu'on ne fait plus de la morphologie, mais bien de la morpho-syntaxe. En effet, dčs lors qu'on travaille sur des séquences de catégories et qu'on introduit le contexte, on passe ontologiquement de l'axe paradigmatique ŕ l'axe syntagmatique, męme si l'axe syntagmatique est appréhendé dans son acception la plus élémentaire, ŕ savoir l'agencement des segments lexicaux sur la chaîne écrite et parlée. Ceci ne retire rien au fait qu'on ait déjŕ basculé dans le champ de la syntaxe.
Voilŕ donc pour le traitement linguistique réalisé par les grammaires de contraintes ŕ des fins de désambiguďsation4. sachant cela, voyons maintenant quelle en est l'incidence sur la représentation des données, donnée internes au moteur de désambiguďsation et données de sortie.
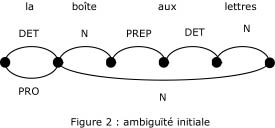
Etant donné que ces grammaires sont dédiées ŕ la désambiguďsation, on calque spontanément le format de l'ambiguďté résiduelle (lorsqu'il y en a) sur le format de l'ambiguďté initiale, ŕ savoir sur les paradigmes d'ambiguďté que ces grammaires ont pour mission de réduire idéalement ŕ un élément.
Or l'ambiguďté initiale est une ambiguďté lexicale, locale au mot, hors-contexte. A chaque segment lexical hérité de la segmentation en mots, on associe (par consultation de dictionnaire et/ou par prédiction) un ensemble d'analyses regroupées dans un paradigme.
La lemmatisation ne fait qu'analyser chacun des segments lexicaux proposés par le segmenteur. Le fait que le segmenteur travaille sur la chaîne de caractčres et propose des alternatives de segmentatioin en relation d'inclusion (entre simples / composés) de chevauchement (entre différents composés) est un autre problčme. C'est un autre type d'ambiguďté situé en amont de la désambiguďsation. Nous ne l'étudierons pas ici, car il n'a pas d'incidence sur la désambiguďsation qui se situe en aval de la lemmatisation. En effet, le désambiguďseur adresse de la męme maničre les unités morphologiques simples, composées ou contractées. Toutes sont identifiées par leur caractérisation morpho-syntaxique : cat, sous-cat, traits flexionnels. Les phénomčnes de surface (composition, contraction, agglutination) sont déjŕ rendus transparents ŕ ce stade d'analyse. C'est tout l'intéręt de la lemmatisation. Chaque fois qu'une rčgle implique un déterminant, tous les déterminants, qu'ils soient contractées ou non ŕ une préposition sont affectés. Męme chose pour les noms qu'ils soient simples ou composés.
Dans tous les cas, les contraintes permettent de restreindre l'ensemble des analyses associées ŕ un segment quel que soit sa nature. Cependant, les contraintes exploitant le contexte font beaucoup plus encore : elles éliminent non seulement des analyses ŕ l'intérieur d'un paradigme d'ambiguďté, mais aussi des séquences d'analyse, des chemins [VOUTILAINEN 93] dans la combinatoire d'analyses.
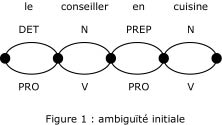
Ainsi, dans "conseiller en cuisine", l'analyse V impératif disparaît pour tous ses contextes gauches, ŕ savoir "en" PREP ou PRO. Par contre, l'analyse PREP de "en" est conservée, mais avec sélection du contexte droit N.

En fait, lorsqu'on applique des contraintes contextuelles, la désambiguďsation consiste non pas ŕ supprimer brutalement une analyse, mais ŕ la lier par la positive ou par la négative ŕ un contexte déterminé. Et ça n'est que l'absence ou la présence de ce contexte dans tous les chemins d'interprétation qui supprime effectivement et définitivement l'analyse.
Aprčs application d'une rčgle de désambiguďsation, l'ambiguďté résiduelle est donc une ambiguďté syntaxique, liée en contexte.
Les automates ŕ états finis expriment de maničre parfaitement efficace les liens qui unissent les unités morphologiques sur la chaîne syntaxique [KOSKENNIEMI 90]. Les états et les transitions traduisent les chemins d'interprétation et chaque fois que certaines ambiguďtés sont liées, le graphe diverge en autant de chemins : chemin DET-N / chemin PRO-V pour notre exemple.
Les graphes acycliques orientés sont donc utilisés pour représenter la grammaire (graphe des impossibles) ainsi que les données désambiguďser (graphes des possibles). La désambiguďsation consiste ŕ modifier le graphe des possibles par intersection avec les graphe des impossibles.
On remarquera que les graphes permettent de représenter indifféremment les deux types d'ambiguďtés que nous avons distinguées :
Si les graphes font quasiment l'unanimité pour la représentation de l'ambiguďté en interne (dans le moteur de désambiguďsation), qu'en est-il en externe des sorties de désambiguďsation ?
Dans le cas d'une désambiguďsation totale, déterministe, aucune ambiguďté résiduelle n'est ŕ gérer. Un seul chemin d'analyse a été préservé par la grammaire. La question du format de l'ambiguďté est caduque.
Dans le cas d'une désambiguďsation partielle, non-déterministe, l'ambiguďté résiduelle doit en revanche pouvoir ętre représentée sans perdre tout ou partie du travail réalisé par la grammaire de désambiguďsation. Or convertir un graphe d'ambiguďtés morpho-syntaxiques liées en un graphe d'ambiguďtés lexicales locales fait perdre de l'information et peut les cas échéant ramener ŕ l'ambiguďté initiale.

Un désambiguďseur peut-il ętre non-déterministe ?
D'un point de vue fonctionnel, cela dépend de deux facteurs : du jeu d'étiquettes manipulé et de la place du désambiguďseur dans la chaîne de traitement.
Le jeu d'étiquettes manipulé par le désambiguďseur est de la plus haute importance. En désambiguďsation, il a des incidences directes sur l'ambiguďté résiduelle. Un jeu d'étiquettes qui regroupe sous la męme étiquette des ambiguďtés difficilement résolubles (N/ADJ = NA, ADJ/Vppé=AJ) et qui catégorise certains mots par leur graphie (que, comme, etc.) a évidemment ŕ faible coűt un taux d'ambiguďté résiduelle trčs faible. Il s'agit donc de savoir si l'on veut faire un simple étiquetage ou une analyse morphologique complčte. Dans le cas d'une analyse morphologique complčte, il est difficile de résoudre toute l'ambiguďté en morphologie, difficile d'ętre déterministe donc.
En ce qui concerne, la chaîne de traitement, un désambiguďseur placé en fin de chaîne, servant de post-traitement morphologique pour l'étiquetage de corpus peut difficilement se permettre le non-déterminisme. L'étiquetage sera de toutes façons révisé manuellement. En revanche, un désambiguďseur placé en milieu de chaîne servant de pré-traitement syntaxique a tout intéręt ŕ ne pas faire de désambiguďsations abusives pour éviter le chaînage d'erreurs et reléguer ŕ l'analyseur syntaxique (voire sémantique) les ambiguďtés qu'il ne peut résoudre sans riques. En effet, taux d'erreurs et taux de désambiguďsation constituent des vases communiquants : au-delŕ d'un certain seuil, on ne fait plus baisser le taux d'ambiguďté sans relever le taux d'erreurs [VOUTILAINEN 92], VOUTILAINEN 94] ce qui est trčs préjudiciable en termes de robustesse [CHANOD 93] et de qualité.
Si l'on s'autorise de l'ambiguďté résiduelle, quel format doit-elle avoir ? Doit-on revenir au format d'ambiguďté locale hors-contexte ou bien conserver le format d'ambiguďté liée, en contexte ?
Il faut bien comprendre tout d'abord que faire un désambiguďseur non-déterministe n'oblige pas nécessairement ŕ gérer l'ambiguďté globale.
En effet, l'ambiguďté globale fait référence ŕ un découpage syntagmatique :
Elle peut aussi faire référence ŕ la longueur de l'énoncé, mais ironie du sort, l'usage ne dit malheureusement pas si l'ambiguďté doit ętre globale ŕ l'énoncé ou globale ŕ un syntagme de niveau quelconque dans la structure syntagmatique.
Quoiqu'il en soit, le terme d'ambiguďé globale présuppose un niveau de représentation syntagmatique arborescent récursif, niveau de représentation qui n'est pas disponible dans les grammaires de désambiguďsation. De plus, si toutes les ambiguďtés globales reposent sur des ambiguďtés liées, toutes les ambiguďtés liées ne sont pas nécessairement déterminées par des ambiguďtés globales. A preuve certains syntagmes nominaux de longueur identique mais d'analyses différentes.
Ex : le plus embarassant DET-ADV-ADJ/DET-N-ADJ.
Par ailleurs, si l'ambiguďté globale n'est pas, par essence męme, du ressort des grammaires de surface, ces derničres en subissent toutefois les conséquences, ce qui se traduit en termes d'ambiguďté liée. Et contrairement aux idées reçues, ce phénomčne n'est pas un simple cas d'école.
En effet, les vrais corpus sont d'une part en typographie pauvre (peu ou pas de diacritiques), et sont d'autre part truffés de phrases nominales et d'impératives infinitives. Du męme coup, l'ambiguďté initiale y est trčs importante et les décisions de désambiguďsation sont parfois impossibles ŕ prendre sauf ŕ introduire des erreurs. Les alternatives DET-N/PRO-V (Ex : la charge) et PREP-N/PRO-V (Ex : un matelas en mousse) sont sur-représentées. Mais il en existe d'autres, notamment l'alternative PREP-N/PRO-V/V-V ŕ cause de l'ambiguďté du "a/ŕ" V/PREP en typographie pauvre (Ex : Une préparation a base de beurre).
En interne comme en externe (cad en sortie), le format d'ambiguďté doit donc pouvoir exprimer l'ambiguďté liée lorsqu'elle est présente, pour permettre une gestion optimale de l'ambiguďté résiduelle et du travail réalisé par la grammaire de désambiguďsation.La lemmatisation travaille sur l'axe paradigmatique (vertical). Les alternatives morphologiques y sont locales ŕ chaque unité textuelle et forment un paradigme d'ambiguďté morpho-lexicale hors-contexte. La morpho-syntaxe introduit rien moins qu'un changement d'axe dans le cours de l'analyse, ŕ savoir le passage du paradigmatique au syntagmatique, "syntagmatique" devant ętre pris dans son acceptation la plus élémentaire qui est le chaînage des éléments sur un axe horizontal de surface. C'est bien ce que formalisent les chemins d'analyse et les graphes d'ambiguďté qui représentent une ambiguďté liée, en contexte.
Tant dans ses traitements que dans ses sorties, la désambiguďsation morpho-syntaxique donne corps et réalité ŕ un niveau d'analyse morpho-syntaxique ŕ part entičre. Ce niveau grâce ŕ elle ne se pose plus comme une simple vue de l'esprit, mais peut bel et bien prétendre ŕ ętre considéré comme une nouvelle interface de données avant l'entrée dans l'analyse syntaxique proprement dite. Tout un programme pour les analyseurs syntaxiques qui n'admettent généralement en entrée que des ambiguďtés lexicales locales.